Linux性能测试之性能测试指标(转载)
1. 系统性能测试指标
1.1. 响应时间
响应时间是指某个请求或操作从发出到接收到反馈所消耗的时间,包括应用服务器(客户端)处理时间、网络传输时间以及数据库服务器处理时间。比如一个页面从点击/输入到完全加载的时间;完成一次增加、删除、修改或者查询动作的事务响应时间等。
一个请求在网络上的传输往往要经历多个网络节点才能到达目标服务器,我们假设请求经历了三个网络节点的传输时间B1、B2、B3,客户端的处理时间为A,服务器的响应时间为C。则一次请求的完整路径可以描述为下图:
graph RL;
服务器C -->|反馈|节点B3-->节点B2-->节点B1-->|反馈|客户端A
客户端A -->|请求| 节点B1-->节点B2-->节点B3-->|请求|服务器C
客户端从发出请求到接收到服务器反馈的完整链路时间为A—>B1—>B2—>B3—>C(节点处理时间都包括接收和发送两个过程)。
则请求的响应时间为:
响应时间=A+B1+B2+B3+C
1.2. 并发
-
并发是指多个用户在同一时期内进行相同的事务处理或操作。由于用户在进行一系列操作流程时有一定的时间间隔(即用户思考时间)或者服务器处理请求有先后顺序,于是,就产生了绝对并发和相对并发概念的区分。
-
绝对并发是指同一时刻(即同一时间点)并发用户对服务器同时发送请求。
-
相对并发是指一段时间内(即同一时间区间)并发用户对服务器发送请求。
-
举个例子,一个并发量为
10000人(可同时容纳10000人)的动物园,这里的并发量是指绝对并发还是相对并发呢?我们很容易理解,这个并发指的是相对并发,因为整个动物园是一个交织的网状结构,出入口、老虎、狮子、大象等各个动物站点都有分流的作用,基本不可能出现出入口或者站点能够同时承载10000人的情况,出入口的并发可能只有200人。 -
因此这个动物园的例子里,并发量
10000是指各个节点的总和,参观者参观动物园有路径的先后顺序,是相对并发的概念。而出入口的并发量是200人,则是指同一时间在出入口能够同时容纳200人,这就是绝对并发的概念。 -
TODO: 这里缺少一张图
-
一般来说,在系统的性能测试中,系统或者模块的并发更多是指相对并发,而接口的并发更倾向于绝对并发。并发性能的概念是指系统、模块或接口稳定运行,不抛出异常情况下所能够承载的并发量。
-
在并发性能测试中常用到并发用户数和并发请求数两个指标。顾名思义,并发用户数是指同一时间(点或区间),系统、模块或接口能够承载的用户数量;并发请求数是指同一时间(点或区间),系统、模块或接口能够承载的请求数量。
1.3. 点击量/点击率
-
点击量是衡量网站流量的一个指标,也就是点击数
clicks,是对网站点击数据的统计。 -
点击率(
Clicks Ratio)也可以叫做点进率(Click-through Rate),它是网站上某一内容被点击的次数与整个网站内容被显示次数之比,即clicks/views。反应了网站上某一页面或内容的受关注程度,经常用来衡量广告的吸引程度。比如公众号的一篇文章被浏览了10w次,文章中的广告链接被点击了2000次,那么这条广告的点击率是2%(2000/100000*100%)。 -
在性能测试领域,点击率(
hit rate)常指单位时间内(每秒钟)页面的点击数,即每秒钟发送的http请求数量,点击率越大对服务器造成的压力也越大,对服务器的性能要求也越高。 -
有些人容易混淆点击率和点击量的概念,比如我们经常会听到有人说某网站的点击率是多多万,实际上这里的点击率指的是点击量,曝光率或者说页面浏览量。
1.4. 吞吐量/吞吐率
-
吞吐量是指系统处理客户请求数量的总和,可以指网络上传输数据包的总和,也可以指业务中客户端与服务器交互数据量的总和。
-
吞吐率是指单位时间内系统处理客户请求的数量,也就是单位时间内的吞吐量。可以从多个维度衡量吞吐率:①业务角度:单位时间(每秒)的请求数或页面数,即请求数/秒或页面数/秒;②网络角度:单位时间(每秒)网络中传输的数据包大小,即字节数/秒等;③系统角度,单位时间内服务器所承受的压力,即系统的负载能力。
-
吞吐率(或吞吐量)是一种多维度量的性能指标,它与请求处理所消耗的CPU、内存、IO和网络带宽都强相关。
1.5. TPS/QPS
-
TPS(Transaction Per Second)是指单位时间(每秒)系统处理的事务量。事务可以是用户自定义的一系列操作或者动作的集合,比如“用户注册“事务是点击注册按钮,填写用户注册信息,点击提交按钮,以及加载注册成功页面的动作集合。 -
QPS(Query Per Second)是指单位时间内查询或访问服务器的次数。 -
TPS和QPS的区别在于一个事务可以包含多次查询或访问服务器,也可以只查询或访问一次服务器。当多次查询或访问时,一个TPS相当于多个QPS;当只查询或访问一次时,一个TPS则等价于一个QPS。
1.6. PV/UV
PV和UV是衡量web网站性能容量的两个重要度量指标,经常用在电子商务网站领域中用来衡量网站的活跃度。
PV(Page View)是页面的浏览量或点击量,用户对系统或者网站任何页面的每一次点击或者访问都会被记录一次浏览量或点击量,对相同页面进行多次访问浏览量或点击量也会进行累计。
UV(Unique Vistor)是系统或者网站的独立访客,一段时间内相同客户端(或PC)访问系统或者网站只会被记录一次,连续重复访问或者浏览多个系统页面次数不会进行累计。
PV和UV按照统计周期划分,可以划分为全天PV、每小时PV、全天UV和每小时UV等。在一些数据或交易量非常庞大的场景中,比如双11或618等全民购物活动时,常常还会统计峰值PV和峰值UV。
2. Linux服务器性能指标
2.1. CPU使用率
-
CPU使用率是单位时间内服务器CPU的使用统计,可以用除CPU空闲时间外其他时间占总CPU时间的百分比来表示,即:
CPU使用率=1-CPU空闲时间/总CPU时间- 命令:#top //top工具间隔3s会动态滚动更新一次数据
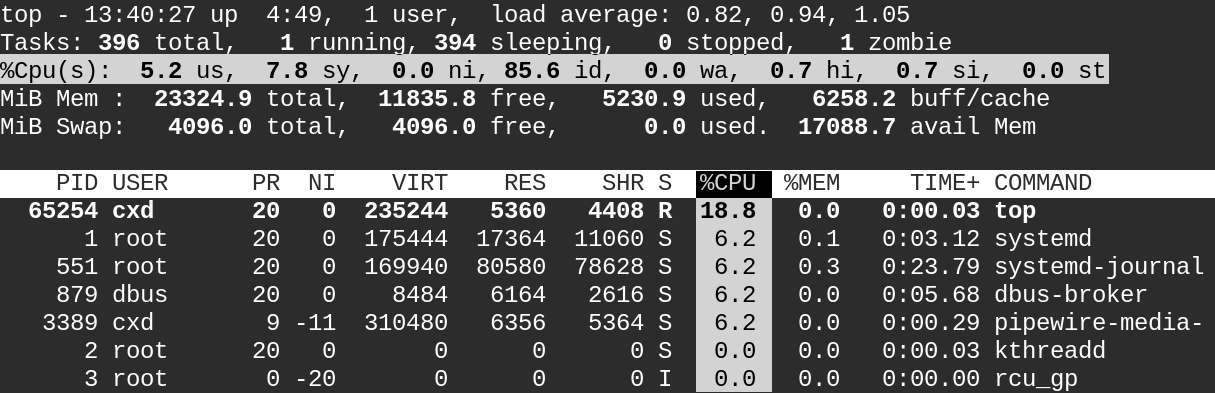
字段 说明 us (user)用户态的CPU使用时间比例,是用户运行程序的真正时间,它不包括后面的ni时间; sy (system)内核态的CPU使用时间比例,是操作系统的运行时间,操作系统运行时,用户运行程序往往处于等待状态; ni (nice)表示低优先级用户态的CPU时间比例,取值范围为[-20,19],数值越大,则优先级越低; id (idle)表示空闲的CPU时间比例,值越大,CPU空闲时间比例越高,利用率越低; wa (iowait)表示处于IO等待状态的CPU时间比例; hi (hard interrupt)表示处理硬中断的CPU时间比例; si (soft interrupt)与hi相反,表示处理软中断的CPU时间比例; st (steal)表示当前系统运行在虚拟机中被其他虚拟机占用的CPU时间比例。
- 命令:#top //top工具间隔3s会动态滚动更新一次数据
-
在性能测试中,系统整体的CPU使用率可以用(1-id)来计算。当us很高时,说明CPU时间主要消耗在用户代码上,可以从用户代码角度考虑优化性能;当sy很高时,说明CPU时间主要消耗在内核上,可以从是否系统调用频繁、CPU进程或线程切换频繁角度考虑性能的优化;当wa很高时,说明有进程在进行频繁的IO操作,可能是磁盘IO或者网络IO。
-
一般情况下,如果
%us+%sy<=70%,我们可以认为系统的运行状态良好。
2.2. 内存占用率
-
Linux的系统内存管理机制遵循内存利用率最大化的原则。内核会将空余的内存划分为cached(不属于free),对于有频繁读取操作的文件或数据会被保存在cached中。因此,对于linux系统来说,可用于分配的内存不止free的内存,同时还包括cached的内存(其实还包括buffers的内存)。
-
cached和buffers都属于缓存,它们的区别主要在于cached主要用来缓冲频繁读取的文件,它可以直接记忆我们打开的文件内容;而buffers主要用来给块设备做的缓冲大小,只记录文件系统的metadata以及tracking in-flight pages信息,比如存储目录里面的内容,权限等。
-
top工具既可以查看系统CPU使用情况,也可以查看系统内存使用信息。
- 命令:#top
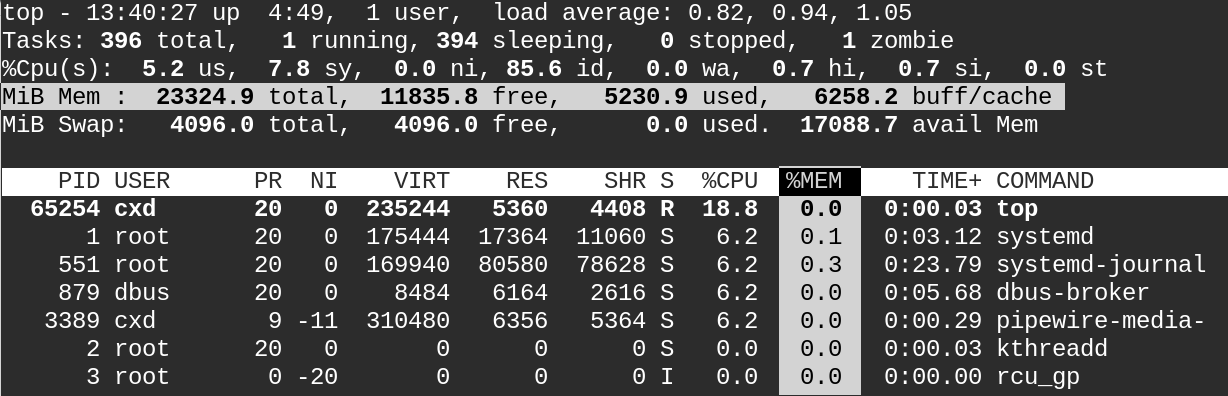
在性能测试中,经常会用到系统已用内存、物理已用内存、系统内存占用率以及物理内存占用率这几个指标,它们的计算公式如下:
系统已用内存MemUsed=MemTotal-MemFree//包含buffers和cached
物理已用内存-/+Used= MemTotal-MemFree-MemBuffers-MemCached
系统内存占用率MemUsed%=(MemUsed/ MemTotal)*100%
物理内存占用率-/+Used%=(-/+Used/ MemTotal)*100%
- 命令:#top
-
一般情况下,
系统内存占用率<=70%,我们可以认为系统的内存使用情况良好,如果超出则说明系统内存资源紧张。
2.3. 系统平均负载
-
当发现系统出现卡断或者运行不顺畅时,我们可以通过uptime,top或者w命令来查看系统的负载情况。
-
uptime

-
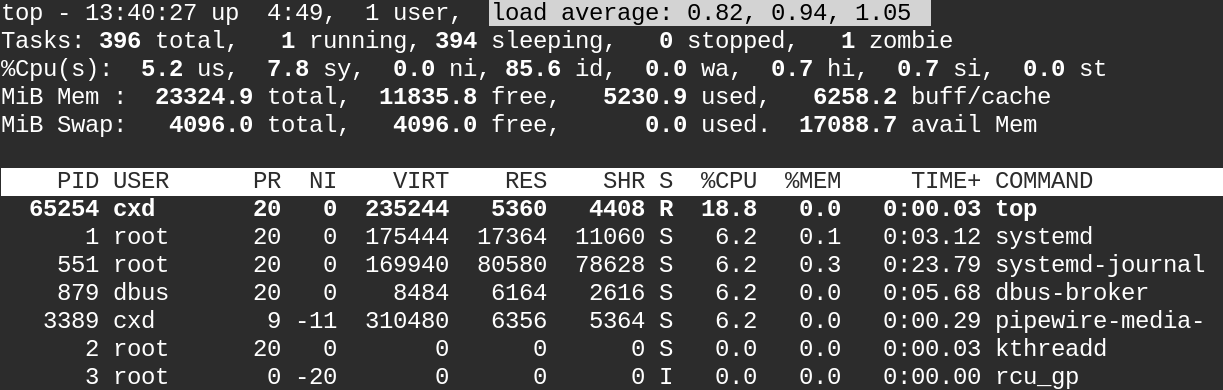
top
-
w

-
Linux的load average表示系统负载的平均值,显示的三个数值分别表示1分钟、5分钟和15分钟内的平均负载情况。这里的平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,可以简单的理解为平均负载就是系统平均活跃进程数。
-
其中可运行状态是指正在使用CPU或者正在等待CPU的进程(处于R状态:Running或者Runnable的进程);不可中断状态的进程指的是正处于内核态关键流程中的进程,处于这个流程的进程是不可打断的,比如等待硬件设备的I/O响应。
-
举个例子,当平均负载的值为4:
- 对于只有1个CPU的系统,意味着平均有3个进程竞争不到CPU;
- 对于拥有4个CPU的系统,意味着CPU利用率为100%;
- 对于拥有8个CPU的系统,意味着CPU利用率为50%,有一半空闲。
-
可以看出,当系统平均负载的值如果超过系统CPU的数量时,那么系统有可能会遇到性能瓶颈,要视具体情况而定。
-
在性能测试中,我们也经常会通过比较1min、5min或者15min的值,来判断系统平均负载的变化情况:
-
如果1min的值大于5min或者15min的值,说明负载在增加;
-
如果1min的值小于5min或者15min的值,说明负载在减小;
2.4. 磁盘IO
-
Linux服务器性能除了CPU和内存外,还有磁盘IO也是一种常用的性能指标。
-
命令:#
iostat –x –k 2 3//每隔2S输出磁盘IO的使用情况,共采样3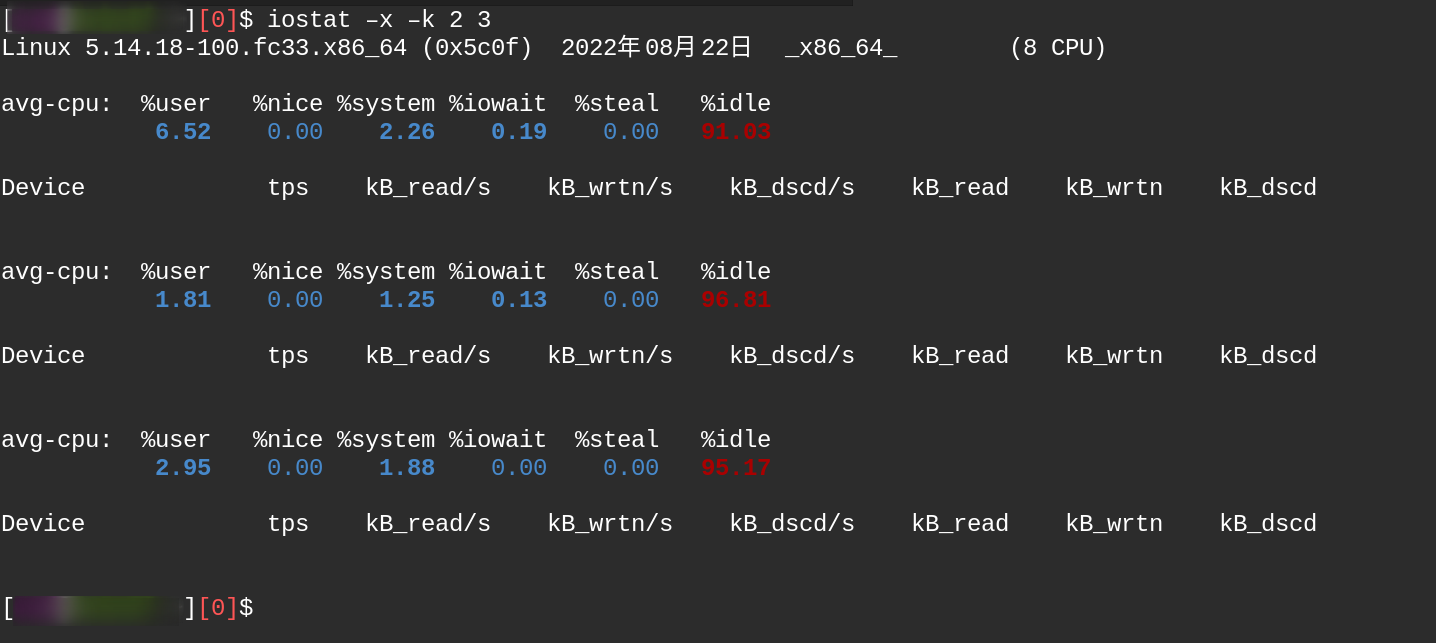
字段 说明 rrqm/s 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并; wrqm/s 每秒对该设备的写请求被合并次数; r/s 每秒完成的读次数; w/s 每秒完成的写次数; rkB/s 每秒读数据量(kB为单位); wkB/s 每秒写数据量(kB为单位); avgrq-sz 平均每次IO操作的数据量(扇区数为单位); avgqu-sz 平均等待处理的IO请求队列长度; await 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位); svctm 平均每次IO请求的处理时间(毫秒为单位); %util 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率; -
在性能测试中,我们可以重点关注
iowait%和%util参数。其中iowait%表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题了;%util表示磁盘忙碌的情况,一般%util<=70%表示该磁盘IO使用状态良好。
2.5. linux常用性能命令
CPU:cat /proc/cpuinfo、top、lscpu内存:cat /proc/meminfo、free、vmstat负载:cat /proc/loadavg、uptime、iostat磁盘:df、du、iostat、fdisk -l整体:vmstat 3 2